Machine learning using H2O
Jun 14, 2020
R
Machine Learning
GBM
H2O
This post will be a quick introduction to using H2O through R. H2O is a platform for machine learning; it is distributed which means it can use all the cores in your computer offering parallelisation out of the box. You can also hook it up to already set up Hadoop or Spark clusters. It is also supposed to be industrial scale and able to cope with large amounts of data.
You can install H2O from CRAN in the usual way using install.packages(). Once you load the package you can initialise a cluster using the h2o.init() command.
require(h2o)
h2o.init()
## Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 2 hours 17 minutes
## H2O cluster timezone: Europe/London
## H2O data parsing timezone: UTC
## H2O cluster version: 3.30.0.1
## H2O cluster version age: 2 months and 10 days
## H2O cluster name: H2O_started_from_R_victor.enciso_ird509
## H2O cluster total nodes: 1
## H2O cluster total memory: 3.26 GB
## H2O cluster total cores: 4
## H2O cluster allowed cores: 4
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: Amazon S3, Algos, AutoML, Core V3, TargetEncoder, Core V4
## R Version: R version 4.0.0 (2020-04-24)
You will get some detail about your cluster as above.
I’ve got a prepared data set that I can load in and start playing around with.
The dataset has 10,000 rows. Using H2O with such a small dataset might be overkill but I just want to illustrate the basics of how it works.
dim(mwTrainSet)
## [1] 10000 28
I preprocess the data using the recipes package as in my xgboost post.
myRecipe<- recipes::recipe(outcome ~ ., data=mwTrainSet) %>%
recipes::step_mutate(os = as.factor(os)) %>%
recipes::step_mutate(ob = as.factor(ob)) %>%
step_rm(id) %>%
step_mutate(w50s = ifelse(ds<=0.5,'TRUE','FALSE')) %>%
prep()
proc_mwTrainSet <- myRecipe %>% bake(mwTrainSet)
proc_mwTestSet <- myRecipe %>% bake(mwTestSet)
Also, I get the names of the predictors in an array which will be used as input when the model is constructed.
predictors <- setdiff(colnames(proc_mwTrainSet), c("outcome"))
The training dataset needs to be converted into an H2O dataset so it can be passed to the model.
train.h2o <- as.h2o(proc_mwTrainSet, destination_frame = "train.h2o")
test.h2o <- as.h2o(proc_mwTestSet, destination_frame = "test.h2o")
Actually, all the preprocessing can be done using H2O specific commands rather than R commands. This will become necessary if your dataset becomes larger.
I’m going to fit a gradient boosted tree model to the dataset. Originally I wanted to use xgboost here but I later discovered that H2O doesn’t support it on Windows. However, if you’re running Linux or OS X then you’re in luck. If you’re set on using it on Windows one solution could be to create a Linux VM.
I specify the gbm model with some parameters I used when I trained the same dataset using xgboost with the rationale that they should translate reasonably well. Note that I’m doing 5-fold cross-validation through the nfolds parameter, I’m building 1000 trees and setting a stopping parameter.
gbm <- h2o.gbm(x = predictors, y = "outcome", training_frame = train.h2o,
ntrees=1000, nfolds = 5 ,max_depth = 6, learn_rate = 0.01
,min_rows = 5, col_sample_rate = 0.8 ,sample_rate = 0.75
,stopping_rounds = 25, seed=2020)
When the cluster is initialised you also get access to a web-based UI. This UI can be accessed locally through a web browser on http://localhost:54321/. In theory you can do all your analysis and build all your models directly in the UI if you want without interacting with R at all.
Having the UI is handy to get a quick view of your model results without running any more commands.
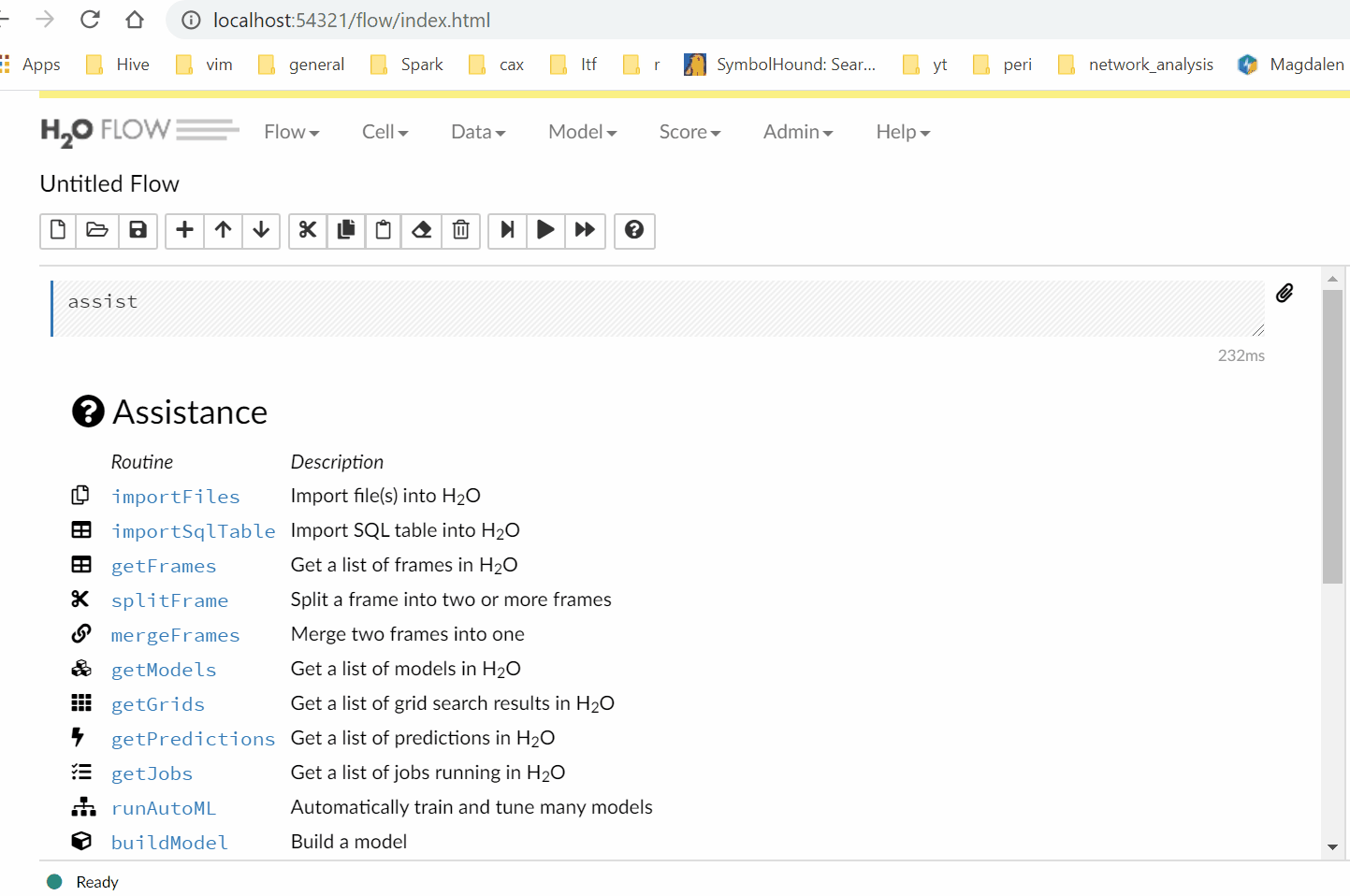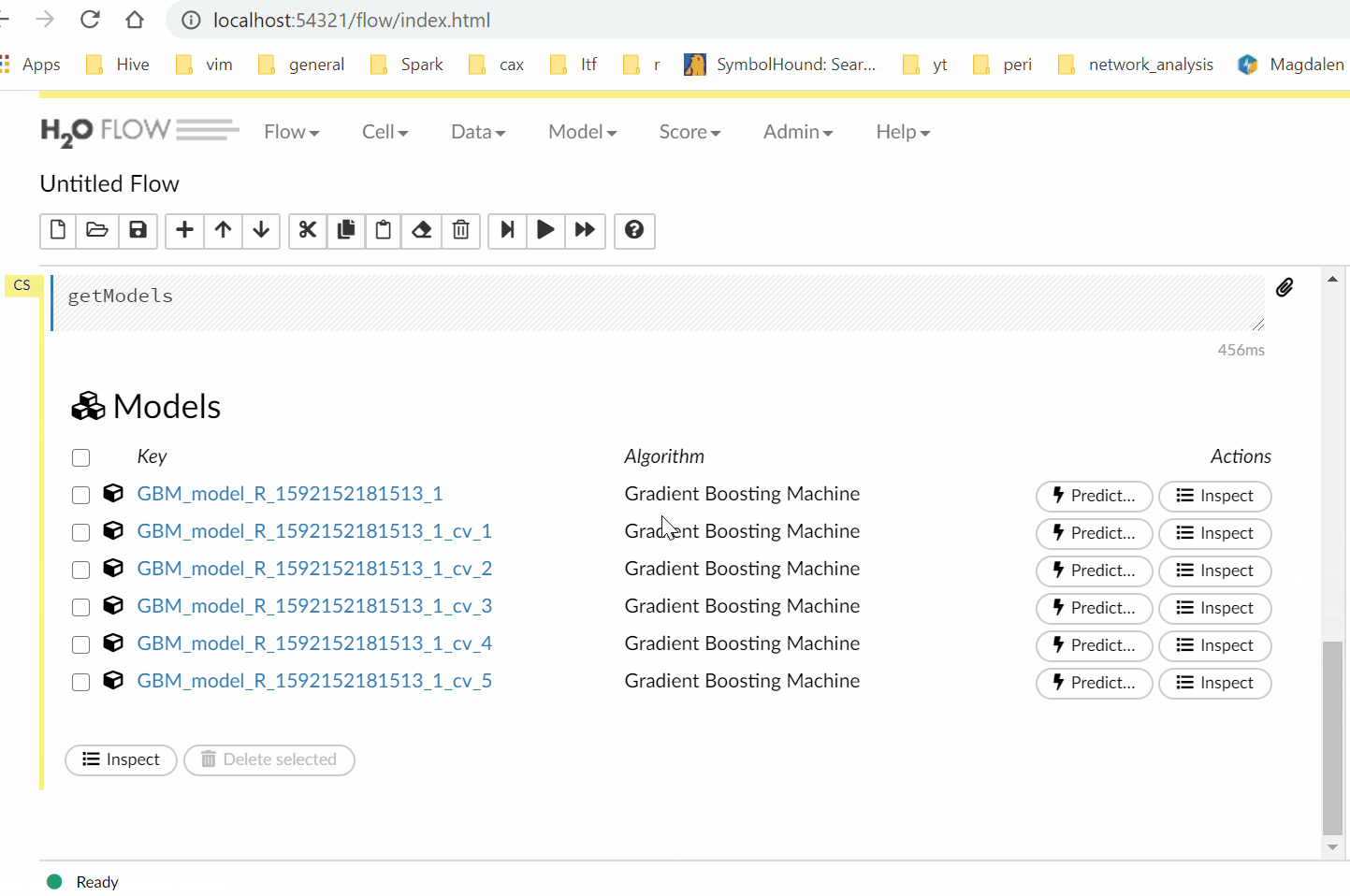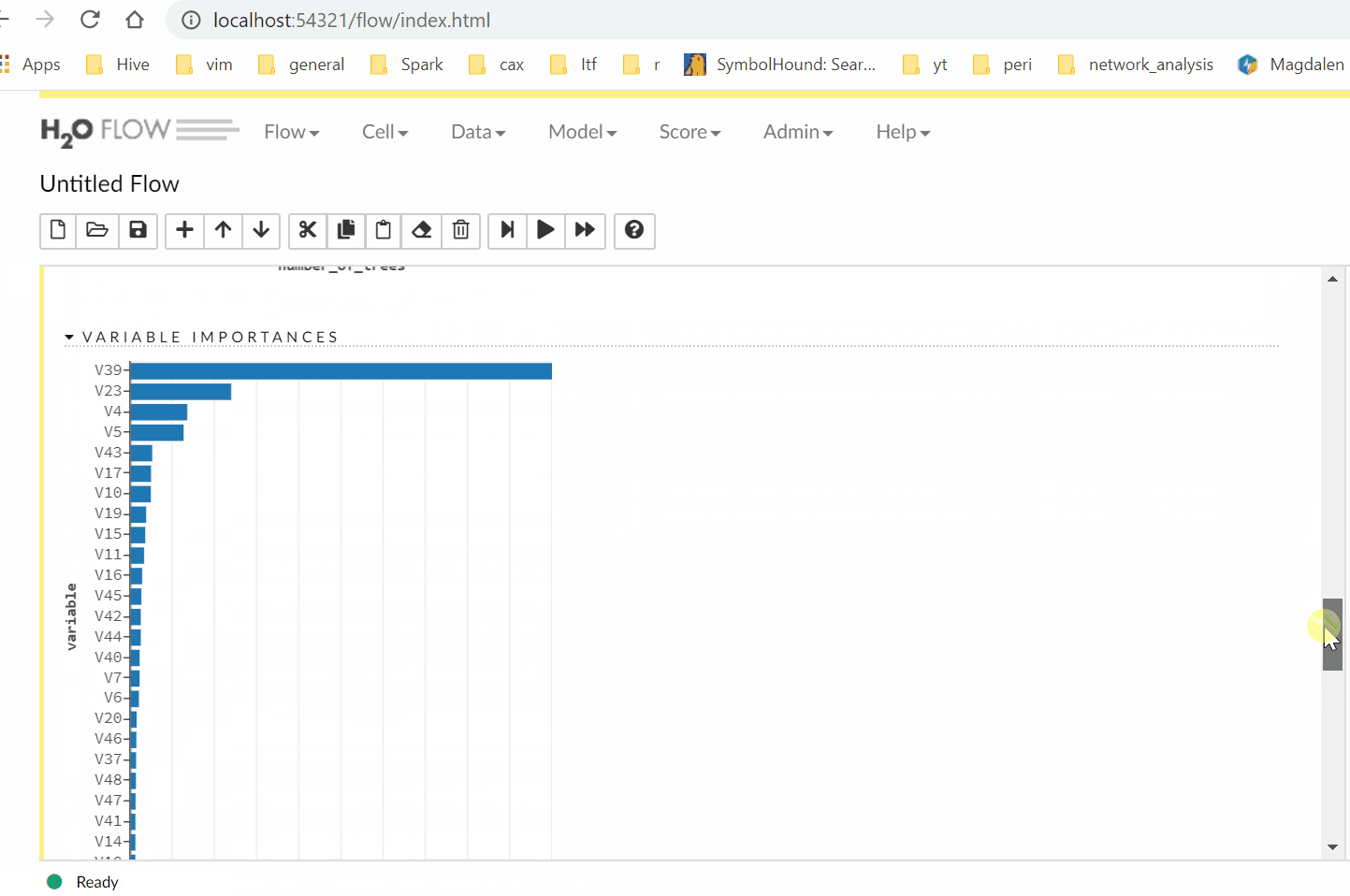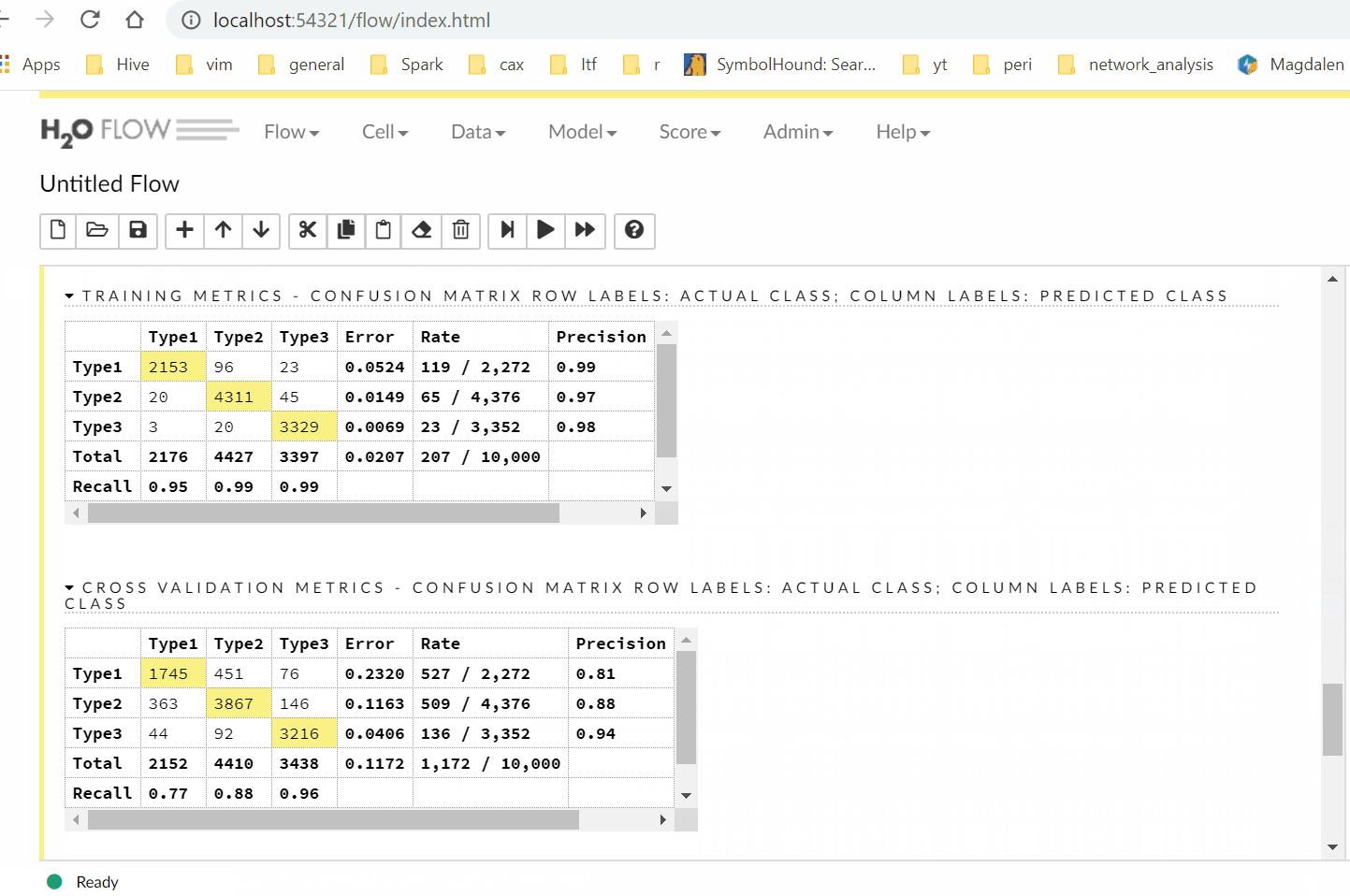
Finally, we can feed new data into the model to get predictions.
pred<-h2o.predict(object = gbm , newdata=test.h2o)
kablify(head(pred,5))
| predict | Type1 | Type2 | Type3 |
|---|---|---|---|
| Type2 | 0.0696576 | 0.9231076 | 0.0072348 |
| Type2 | 0.0051987 | 0.9566815 | 0.0381198 |
| Type2 | 0.0082406 | 0.9884921 | 0.0032673 |
| Type2 | 0.0118451 | 0.9852316 | 0.0029233 |
| Type2 | 0.1531306 | 0.8428315 | 0.0040379 |
I don’t actually know the labels of my test set but if I did I could use the following to get the performance in the test set
h2o.performance(model = gbm, newdata = test.h2o)
Once all the work is done we shut down the cluster
h2o.shutdown()
## Are you sure you want to shutdown the H2O instance running at http://localhost:54321/ (Y/N)?
That will do for now. This was a very light introduction into H2O, one more tool to be aware of if you work with machine learning.